MotionBoardのWebAPIを使ってMotionBoardのデータをDataSpiderで外部に出力する
Ryosuke Ishii
データパレード


下記記事にて、AWSのLambdaから外部サービスのAPIをコールし、結果をS3にCSVとして格納する方法について紹介しました。
日毎にCSVが分かれておりこのままでは分析しづらいためデータベースに格納していきます。本記事ではSnowflake側へS3にあるCSVファイルをインポートする方法を紹介します。
S3にあるファイルをSnowflakeから取得する方法は公式ページで紹介されています。
ベストプラクティスな構成としてAWSの通知の仕組みなども含まれていますが、本記事ではシンプルにS3からファイルをインポート、スケジューリングする部分のみ紹介します。
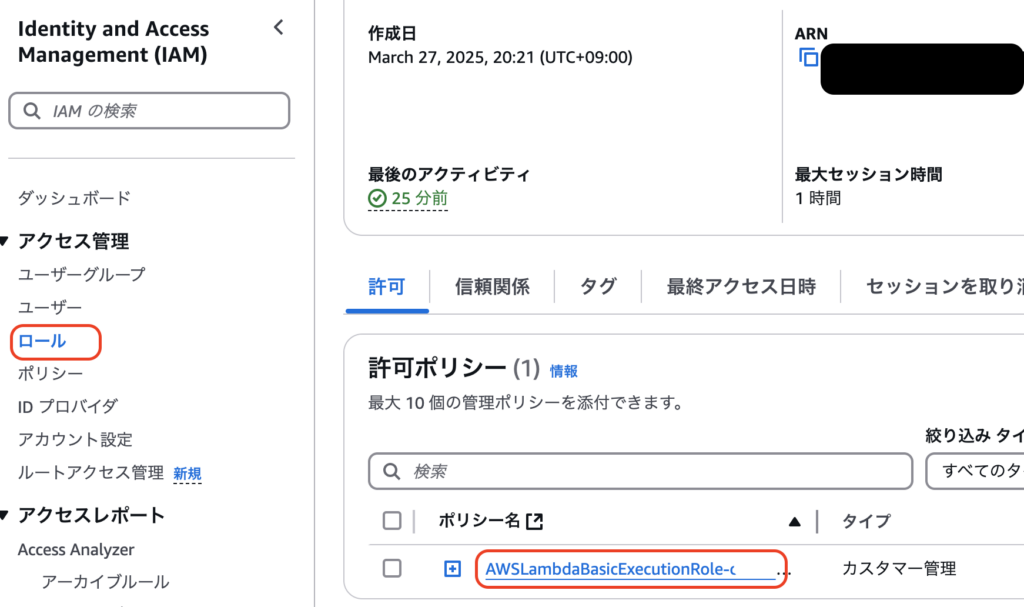
まずはロールがS3へアクセスできるよう権限を追加します。AWSから「IAM」のメニュー画面へ遷移し「ロール」をクリック、許可ポリシー欄にあるポリシーを選択します。
本記事の冒頭に貼り付けた記事内で、Lambda関数作成時に自動でポリシーを作成したので、「AWSLambdaBaisc…」というポリシーがあればそちらを選択します。
「許可」タブからJSONを編集します。S3にアクセスするよう下記のエンティティを追加します。
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::[バケット名]/*",
"arn:aws:s3:::[バケット名]"
]
}すでにLambda関数からS3へCSVを配置する権限「PutObject」がある場合は、そのまま大括弧でカンマ区切りのリストで追記してください。
Resourceでは許可するバケットのARNを記述してください。(例:arn:aws:s3:::dataparade)
次にSnowflake側に外部アクセス用のintegrationを作成します。SQL WorksheetもしくはNotebookのSQLセルを開き、下記を入力、環境に合わせて編集し実行します。
CREATE OR REPLACE STORAGE INTEGRATION dataparade_s3_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::************:role/service-role/instagram_for_ichibanhanten-role-*******'
STORAGE_ALLOWED_LOCATIONS = ('s3://[バケット名]/');integrationの名前は任意、STORAGE_AWS_ROLE_ARNには前章でポリシーを追記したロールのARNを指定します。STORAGE_ALLOWED_LOCATIONSにはアクセスを許可するS3バケットのパスを指定します。
integrationの確認を行います。下記を実行して結果を確認してください。
DESC STORAGE INTEGRATION dataparade_s3_integration;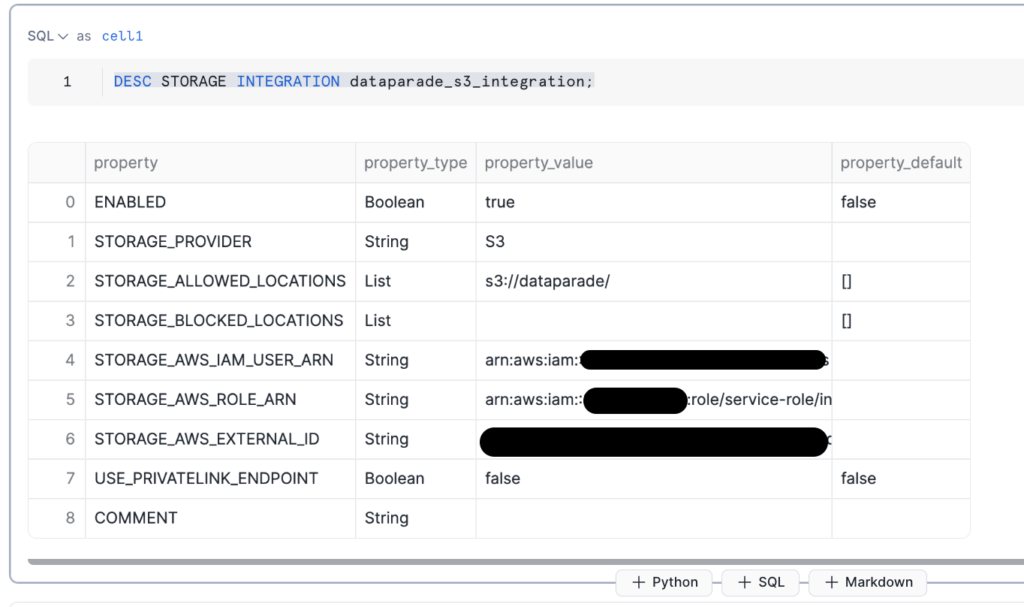
STORAGE_AWS_IAM_USER_ARNおよびSTORAGE_AWS_EXTERNAL_IDは次節で使うので控えておきましょう。
再びAWSの画面に戻ります。IAMの「ロール」画面から許可するロールを選び、「信頼関係」タブを開きます。「信頼ポリシーの編集」から、下記のエンティティを追記します。
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "<snowflake_user_arn>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<snowflake_external_id>"
}
}
}snowflake_user_arnにはSTORAGE_AWS_IAM_USER_ARNを、snowflake_external_idには記録した STORAGE_AWS_EXTERNAL_IDを指定します。
最後にS3のファイルをSnowflake上で参照できるようステージを作成します。下記のSQLを実行します。バケット名およびintegrationの名前は適宜変更します。
CREATE OR REPLACE STAGE dataparade_s3_stage
URL = 's3://[バケット名]/'
STORAGE_INTEGRATION = dataparade_s3_integration;以上で準備は終了です!
ではSnowflakeからデータをインポートできるか確認しましょう。下記のようにCOPY INTO文からCSVファイルを参照し、テーブルへインポートします。CSVのパスは適宜変更ください。
COPY INTO [スキーマ].[テーブル名] FROM @dataparade_s3_stage/ichibanhanten/2025/04/05/profile.csv FILE_FORMAT = (TYPE = CSV, FIELD_OPTIONALLY_ENCLOSED_BY='"', SKIP_HEADER=1);ポイントは前章の最後に作成したステージ(例:dataparade_s3_stage」)を@で参照し、パスとして指定する部分です。「FORMAT=…」はヘッダの位置などCSVに合わせて指定します。
クエリの結果として以下の出力、さらにテーブルにデータがインポートされていることが確認できればOKです。

では最後にタスク化して日次などで動かせるようにしていきます。前章でも分かる通り、S3にCSVを格納するパスは日付ごとに分かれるようになっています。
下記の例で言うと「2025/04/06」の部分です。
@dataparade_s3_stage/ichibanhanten/2025/04/06/profile.csvCOPY INTOが実行される際この日付の部分は動的に変更されるようにしたいです。冒頭の記事と同様に、実行するSQLをNotebookに記載してそのままスケジュール実行していきます。
新しいNoteBookを作成し、下記のSQLを実行します。
SET stage_name = '@dataparade_s3_stage';
SET client_name = 'ichibanhanten';
SET today_path = TO_CHAR(CURRENT_DATE - 1, 'YYYY/MM/DD');
SET file_name = 'profile';
SET sql_stmt = 'COPY INTO ICHIBANHANTEN.PROFILE_TEST_FOR_S3_IMPORT FROM ' || $stage_name || '/' || $client_name || '/' || $today_path || '/' || $file_name || '.csv FILE_FORMAT = (TYPE = CSV, FIELD_OPTIONALLY_ENCLOSED_BY=''"'', SKIP_HEADER=1);';
EXECUTE IMMEDIATE $sql_stmt;SET文で日付を取得する変数を定義し、それらを使ってCOPY文を作成、EXECUTEコマンドで実行します。
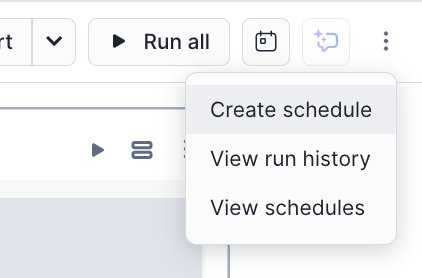
もんだいなければ、右上のカレンダーアイコンから実行タイミングを指定して終了です。
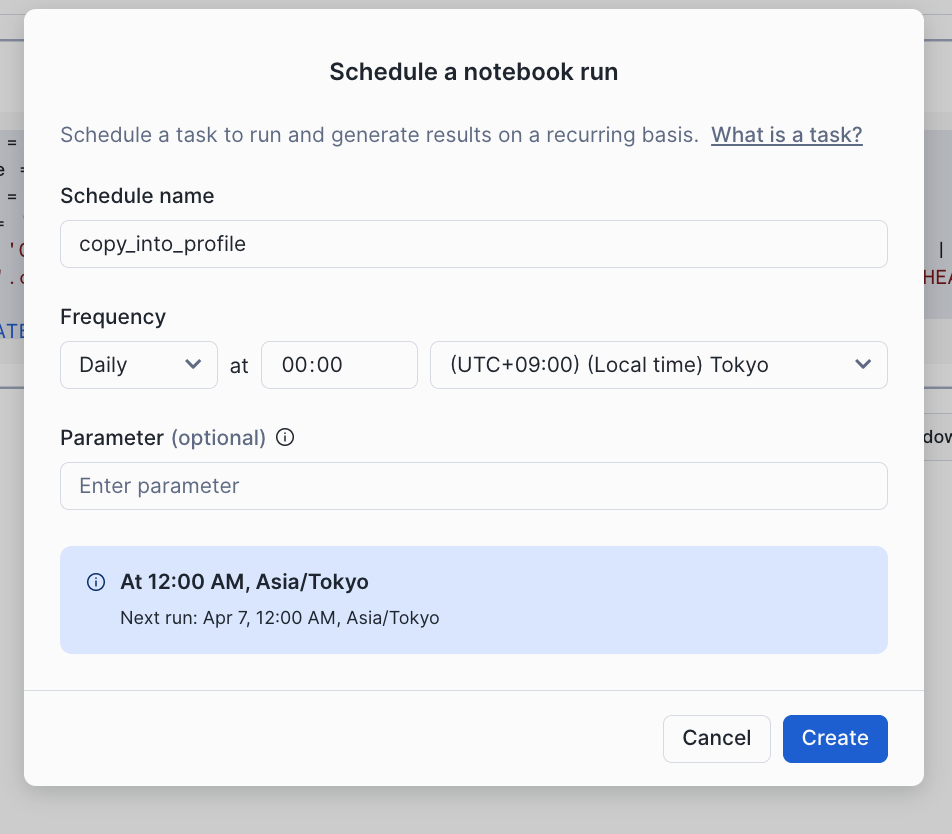
注意点として、stageを作るSQL(以下に再掲)も日次に実行するタスクの中に含めておきましょう。でないと、「’HOGEHOGE_INTEGRATION’ does not exist or not authorized.」といったエラーが出てしまいます。
CREATE OR REPLACE STAGE dataparade_s3_stage
URL = 's3://[バケット名]/'
STORAGE_INTEGRATION = dataparade_s3_integration;本記事では、S3にあるCSVをSnowflakeから参照しテーブルへ格納する方法についてしょうかいしました。また、動的なCSVパスを指定しつつタスク化の方法について紹介しました。Lambdaで外部サービスからデータを取得、S3へ格納→Snowflakeのテーブルへ連携(本記事の内容)の低コストかつシンプルな構成で活用の幅を広げてみてくださいね!