データ活用推進者が知っておきたいデータの管理とは?
Ryosuke Ishii
データパレード

システムからダウンロードしたCSVファイルをチームが管理するGoogle Driveなどに格納し、Google Sheet上で加工して全体へ共有するといったケースはよくあります。その場合、アップロードするファイルが多かったり、各CSVファイルをGoogle Sheet化する必要があったりと、すべて手動で実施するには大変なことも多いです。
本記事ではPythonを使って、CSVファイルを読み取りGoogle Sheetに格納する仕組みを紹介します。実際のシーンを考えると、格納するといっても以下2つの方法が考えられます。
①Google Sheetの内容をCSVファイルデータですべて上書きする
②Google Sheetの末尾にCSVファイルの内容を追記する
今回はこれら2つの方法を含めた自動化の方法を紹介します。
Google Drive上のGoogle Sheetにアクセスするために、いくつか事前設定が必要です。「Google Sheet Python アクセス」などと検索するとヒットするかと思いますので、本記事では割愛します。
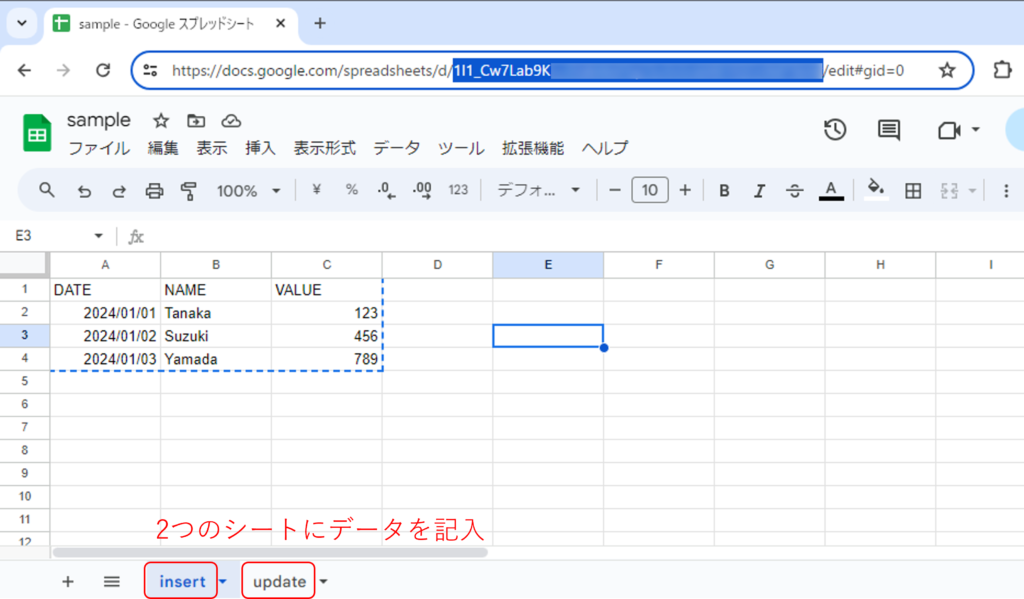
続いてサンプルCSVを格納する先として、「sample」という名前のGoogle Sheetを作成し、「insert」および「update」というシートを作成します。また、サンプルとしてDATE/NAME/VALUEの3列にデータを記入しています。
記事で紹介するプログラムやデータは下記からダウンロード可能です。書き込み先のGoogle Sheetの指定などはJSONファイルに記載します。詳細はREADME.txtをご覧ください。
Google Sheetのキー情報(GSS_KEY)は、URLから取得できます。URL中の文字列をコピー&ペーストしてください。
前章のサンプルフォルダでは、メインとサブの2つのスクリプトからなっています。メインスクリプトでは、ユーザーが指定したパラメータやJSONファイルの内容に沿って処理を行います。ライブラリは適宜インストールしてくださいね!
pip install oauth2client
pip install gspread
pip install gspread-dataframefrom my_modules.to_GSS import to_GSS
import pandas as pd
import argparse, json
# import sys, os
import datetime
import logging
parser = argparse.ArgumentParser(description='This script is hogehoge')
parser.add_argument('-configfile_path', help = "Set path including config json file name e.g. C:/Users/hogehoge/config.json", required = True)
parser.add_argument('-key_name', help = "Set key name e.g. 'ME'", required = True)
parser.add_argument('-csv_path', help = "Set path including config json file name e.g. C:/Users/hogehoge/config.json", required = True)
parser.add_argument('--add_date_for_today', help = "add date for today", action = "store_true")
parser.add_argument('--columnname_adding_date', help = "set column name for adding date", default = "date_get_data")
args = parser.parse_args()
configfile_path = args.configfile_path
with open(configfile_path, "r") as f:
configs = json.load(f)
key_name = args.key_name
csv_path = args.csv_path
add_date_for_today = args.add_date_for_today
columnname_adding_date = args.columnname_adding_date
with open(configs['GOOGLE_SPREAD_SHEET']['JSON_PATH'], "r") as f:
CONFIG_GSS = json.load(f)
# ------------------------ ログ出力パラメータ ------------------------
month = datetime.datetime.now().strftime('%m')
formatter = '%(levelname)s : %(asctime)s : %(message)s'
logFilePath = configs['COMMON']['LOG']["PATH"] + configs['COMMON']["LOG"]['PREFIX'] + '_' + month + '.log'
logging.basicConfig(filename=logFilePath,level=logging.INFO,format=formatter)
def main():
to_gss = to_GSS(CONFIG_GSS)
to_gss.auth() # シートの操作権を取得
today = datetime.datetime.strftime(datetime.datetime.now(), "%Y/%m/%d")
df = pd.read_csv(csv_path)
if add_date_for_today:
df[columnname_adding_date] = [today for i in range(len(df))]
configs_gss = configs['GOOGLE_SPREAD_SHEET']
for c in configs_gss[key_name]["TO_STR"]:
df[c] = [str(v) for v in df[c]]
print(df.head())
if (configs_gss[key_name]["IMPORT_MODE"] == "INSERT"):
to_gss.bulk_insert(configs_gss[key_name]["GSS_KEY"], configs_gss[key_name]["SHEET_NAME"], df.values.tolist())
print(f"Successfully insert {key_name} to GSS")
logging.info(f"Successfully insert {key_name} to GSS")
elif(configs_gss[key_name]["IMPORT_MODE"] == "UPDATE"):
to_gss.flush_exchange(configs_gss[key_name]["GSS_KEY"], configs_gss[key_name]["SHEET_NAME"], df)
print(f"Successfully flush exchange {key_name} to GSS")
logging.info(f"Successfully flush exchange {key_name} to GSS")
else:
print(f"Error. IMPORT_MODE must be set 'INSERT' or 'UPDATE'. ")
logging.error(f"Error. IMPORT_MODE must be set 'INSERT' or 'UPDATE'. ")
if __name__ == '__main__':
main()続いてサブのスクリプトも紹介します。サンプルのZIPファイル内のmy_modulesフォルダにあります。メインのスクリプトはこちらに定義された関数を呼出しています。
import gspread
import gspread_dataframe
from oauth2client.service_account import ServiceAccountCredentials
import pandas as pd
class to_GSS:
def __init__(self, config :dict) -> None:
self.config = config
def auth(self):
#jsonファイルを使って認証情報を取得
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
c = ServiceAccountCredentials.from_json_keyfile_dict(self.config, scope)
# c = ServiceAccountCredentials.from_json_keyfile_name(key_json_file, scope)
#認証情報を使ってスプレッドシートの操作権を取得
self.gs = gspread.authorize(c)
def bulk_insert(self, spreadsheet_key: str, gss_sheet_name: str, data: list) -> None:
"""bulk insert to gss starts at last row automatically.
Args:
spreadsheet_key (str): _description_
gss_sheet_name (str): _description_
data (list): 2d array list. e.g., [["2023/01/01", "aaa", 300], ["2023/02/02", "bbb", 400], ...]
"""
worksheet = self.gs.open_by_key(spreadsheet_key)
worksheet.values_append(
gss_sheet_name,
{"valueInputOption": "USER_ENTERED"},
{"values": data}
)
def flush_exchange(self, spreadsheet_key: str, gss_sheet_name: str, df: pd.DataFrame) -> None:
"""flush and exchange (全件洗い替え)
Args:
spreadsheet_key (str): _description_
gss_sheet_name (str): _description_
df (pd.DataFrame): _description_
Returns:
_type_: _description_
"""
worksheet = self.gs.open_by_key(spreadsheet_key).worksheet(gss_sheet_name)
worksheet.clear()
gspread_dataframe.set_with_dataframe(worksheet, df)
# worksheetの情報を返す関数
def get_gss_worksheet(self, spreadsheet_key: str, gss_sheet_name: str) -> gspread.worksheet.Worksheet:
# スプレッドシート名をもとに、キーを設定
# if gss_name == file_name:
# spreadsheet_key = key_json_file
#共有したスプレッドシートのキーを使ってシートの情報を取得
worksheet = self.gs.open_by_key(spreadsheet_key).worksheet(gss_sheet_name)
# worksheet = gs.open_by_key(spreadsheet_key)
return worksheet
def worksheet_2_dataframe(self, worksheet: gspread.worksheet.Worksheet) -> pd.core.frame.DataFrame:
return pd.DataFrame(worksheet.get_all_records())
下記はJSONファイルの一例です。
{
"GOOGLE_SPREAD_SHEET": {
"JSON_PATH" : "./configs/sound-paratext-123456-abcdefg123456.json",
"INSERT_SAMPLE" :{
"GSS_KEY" : "1I1_Cw7Lab9K・・・",
"SHEET_NAME" : "insert",
"TO_STR" : [],
"IMPORT_MODE" : "INSERT"
},
"UPDATE_SAMPLE" : {
"GSS_KEY" : "1I1_Cw7Lab9K・・・",
"SHEET_NAME" : "update",
"TO_STR" : [],
"IMPORT_MODE" : "UPDATE"
}
},
"COMMON" : {
"LOG" : {
"PATH" : "./log/",
"PREFIX" : "my_log"
},
"DEBUG" : {
"CSV" : "./test.csv"
}
}
}下記は実行コマンドのサンプルです。引数に格納するCSVファイルを指定します。
・追記
python ./csv2gss_main.py -configfile_path "C:\for_writing_article\csv2GSS\configs\config.json" -key_name "INSERT_SAMPLE" -csv_path "C:\for_writing_article\csv2GSS\data\sample.csv" --add_date_for_today・上書き
python ./csv2gss_main.py -configfile_path "C:\for_writing_article\csv2GSS\configs\config.json" -key_name "UPDATE_SAMPLE" -csv_path "C:\for_writing_article\csv2GSS\data\sample.csv" --add_date_for_today実行後、下記のように表示されれば成功です。

前節で追記・上書きするコマンドをそれぞれ実行してみましょう。
「insert」シートではデータの末尾にCSVファイルの内容が追記されています。コマンドを実行した日付(例では2024/02/04)が新しい列に追加されています。
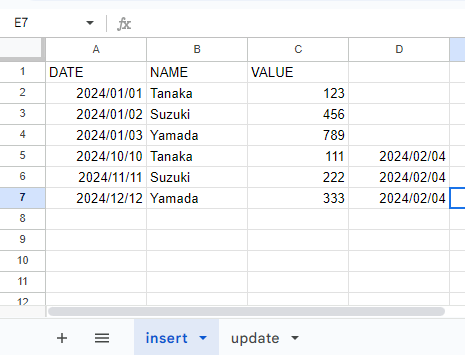
「update」シートでは、CSVの内容が丸々上書きされています。
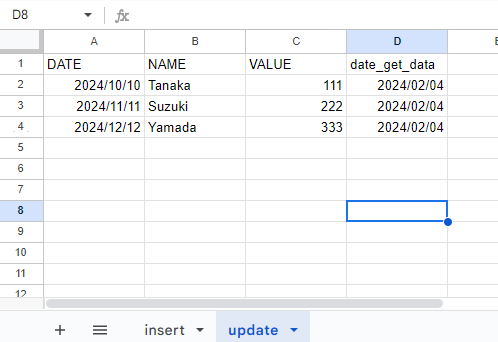
追加 or 上書きかといったシートへの格納方式は、JSONファイルにてそれぞれ設定できるようになっているので、実際のシーンでもぜひ使ってみてくださいね。
本記事では、PythonプログラムからCSVファイルを所望のGoogle Sheetに格納する仕組みを紹介しました。チームでのファイル共有をより効率化させたい場合に是非ご利用ください!