【Oura Ring×Web API】毎日のアクティビティを可視化しよう!【歩数, 消費カロリー, 着座時間, etc.】
えび
データパレード

本記事では、AWSサービス上で外部サービスのデータを取得、格納までを行う方法を紹介します。Snowflakeにデータを格納する上でコンピューティングコストをAWS側に寄せ、コストを抑えることが本記事の目的です。
AWSの主なサービスは以下で、リクエストに対する課金コストが比較的割安な印象です。
本旨の紹介に入る前に背景的なところを次章で書いておきます。
こちらの記事ではSnowflake上のPython実行機能を使って外部サービス(Instagram)からデータを取得する方法について紹介しました。

Pythonの結果をそのままSQLから参照でき、INSERT文を使ってデータ格納までできる点はとても便利です。
しかし、Snowflakeは一行ずつの挿入処理は苦手です。コンピューティング時間が課金要素であるSnowflakeにおいて、件数が多くなってくると処理時間が増えて思わぬ出費につながります。
Snowflakeでは複数件のデータは一括インポートすることが速度面で効果的かつ推奨されています。ひいては課金額を節約することもできそうです。
そこで、Snowflakeと親和性の高いAWS上で、データ取得(by Python)から格納(as CSV)までを行い、その後SnowflakeからCSVを読み取り一括でインポートする方式を構築します。本記事のモチベーションは「課金コストを下げること」です。
上記を踏まえて、本記事にてAWS側の構築について紹介します。
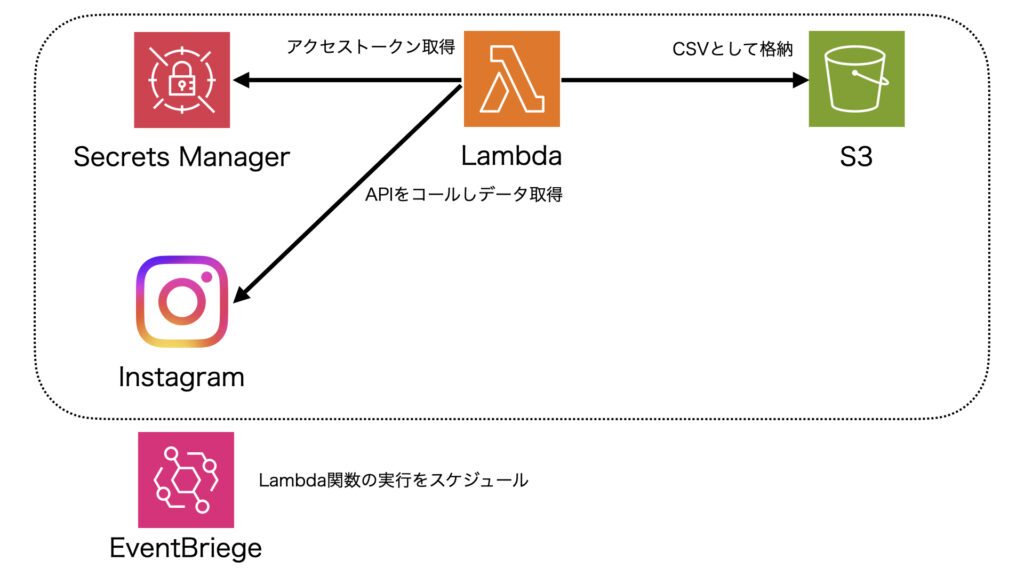
では冒頭の構成図(以下に再掲)にそって各種サービスについて触れていきます。
本記事で紹介する構成は一例です。本番利用を想定する場合などはAWSにおけるベストプラクティスについてご精査ください。
まずはAWSのホームの左上のBentoメニュー(点が9個のボタン)をクリックし、Lambdaサービスを検索、選択します。
「関数を作成」ボタンから関数選択画面へ移動します。下記のように設定してください。
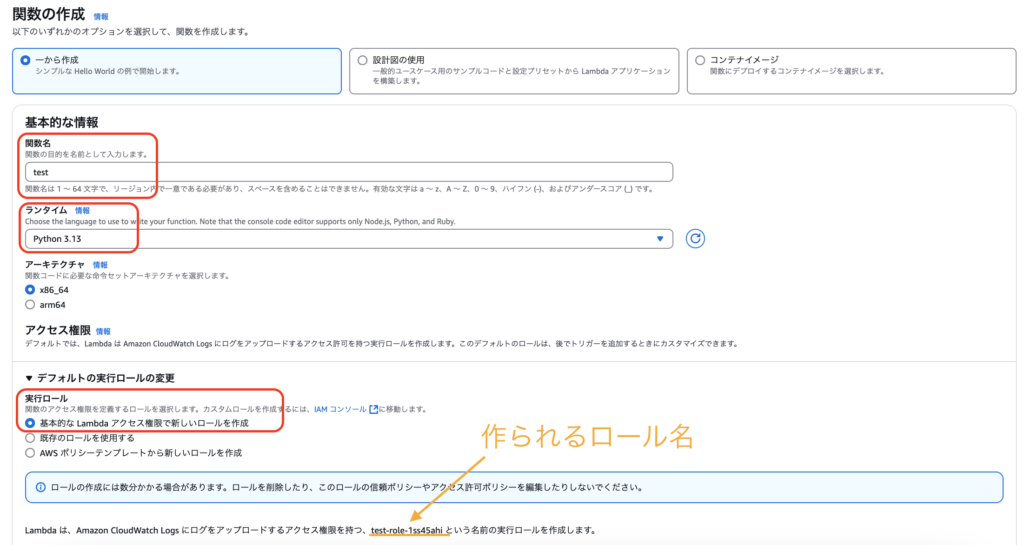
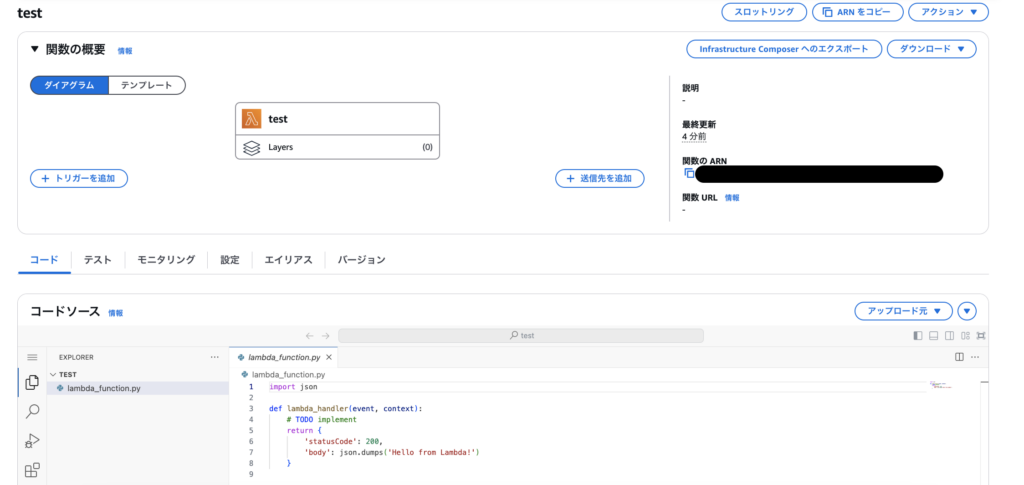
設定後「関数を作成」ボタンを押下します。問題なく作成できれば下記のようなコード記述画面に移りますが、一度Lambdaの画面は離れ次章のS3の設定に進みます。
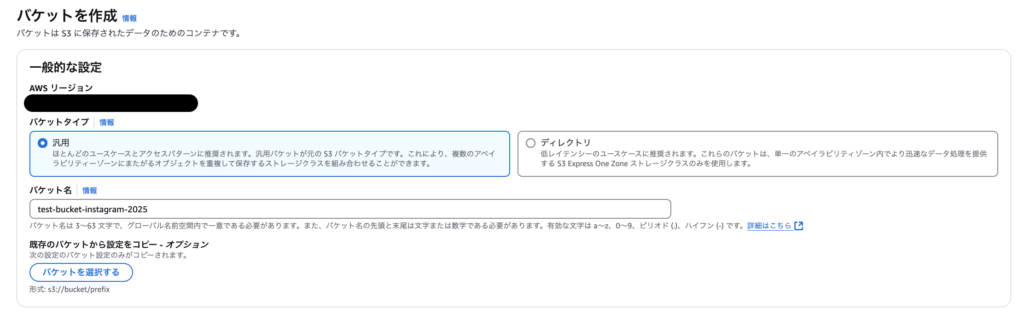
同様に、AWSのページ左上のアイコンからS3のサービスを開きます。「バケットの作成」から任意のバケット名を指定しバケットを作成します。その他の設定は基本的にデフォルトでOKです。
LambdaからInstagramのAPIをコールするためにアクセストークンが必要になります。無論、このアクセストークンは機密情報です。LambdaのPythonコード上にハードコードする方法が考えられますが、セキュリティ的にリスクがあります。
方法としては以下の2つが考えられます。
①の方法はLambdaのコード画面から画像左下のように環境変数を指定する方法です。
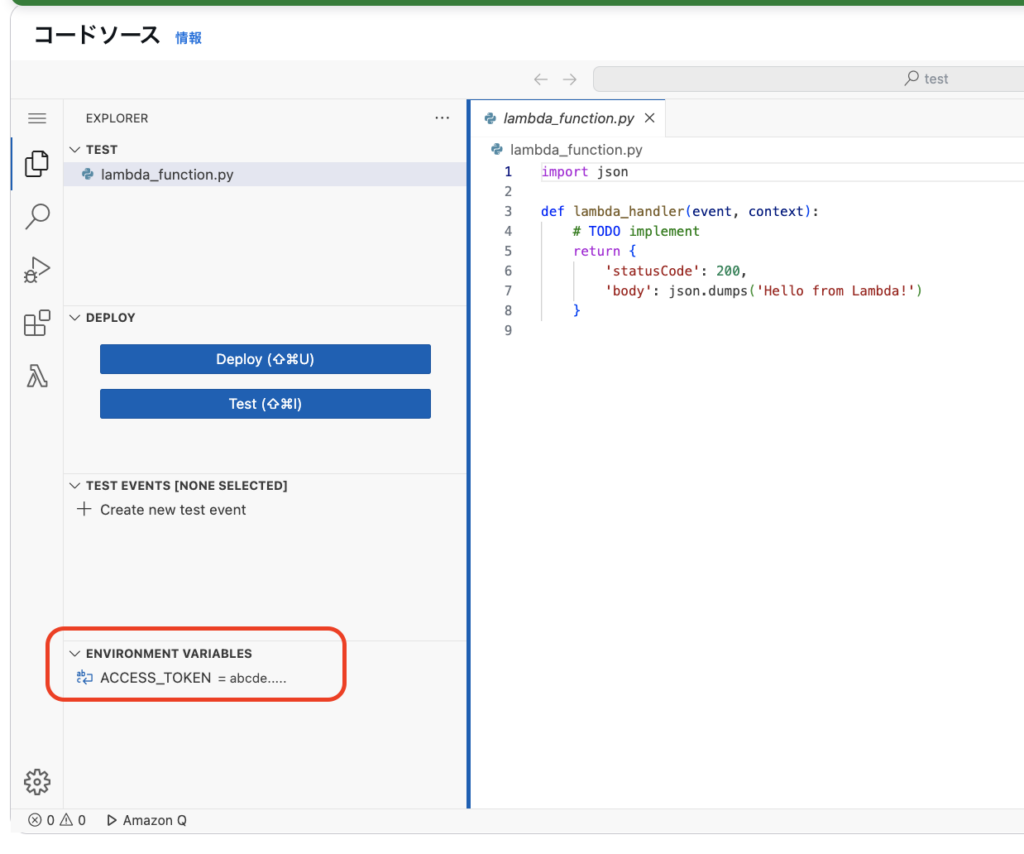
この場合、クライアントごと(Instagramでいうとアカウントごと)にLambdaの関数を作成する必要があります。Pythonの役割自体は「サービスからデータを取得すること」なので、本来クライアントごとに関数が別れるのは適切ではありません。
Lambda関数自体は汎用的に使いまわせるよう1つだけ定義し、入力パラメータで動的にアクセストークンを取得する方がシンプルです。上記を実現しつつ、アクセストークンなどセキュアな情報を格納し適宜利用する方法が②です。
シークレット作成の前にキーを登録します。メニューから「KMS」などと入力し、「Key Management Service」開きます。設定するのは大きく3つです
メニューから「Secrets Manager」を開き、「新しいシークレットを保存する」を押下します。
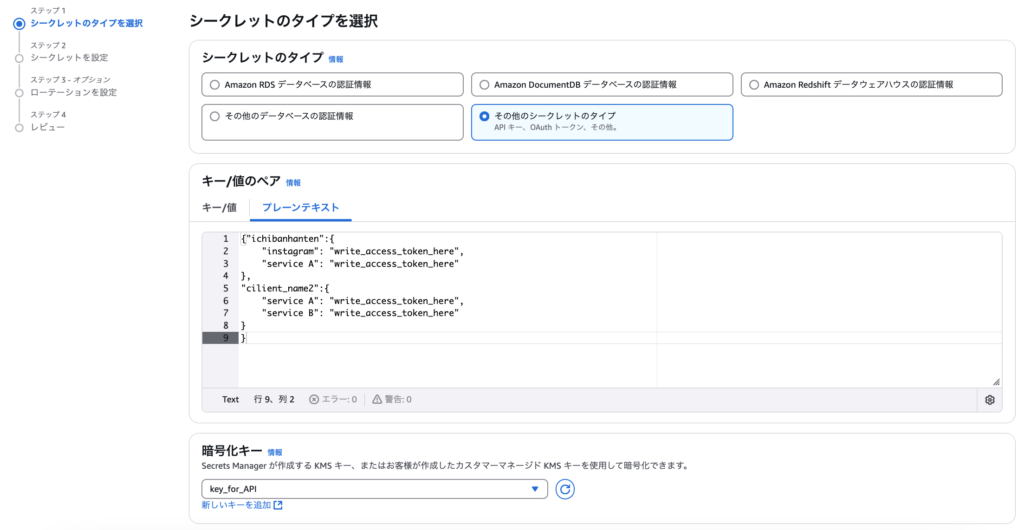
キー/値のペアには、今回Pythonの辞書型として扱いやすいようJSON形式のテキストとしています。下記のように、クライアント-サービス名のような形式にしておきます。
{
"ichibanhanten": {
"instagram": "write_access_token_here",
"service A": "write_access_token_here"
},
"cilient_name2": {
"service A": "write_access_token_here",
"service B": "write_access_token_here"
}
}最後にシークレットの名前を指定します。
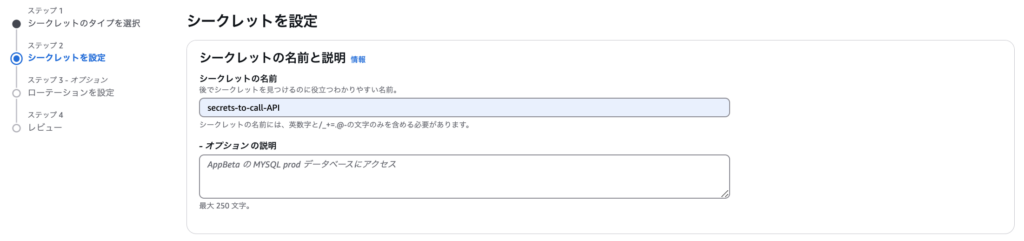
ここで、Secrets Managerからの値取得およびS3へのCSV格納権限をロールに対して付与します。
メニューからIAMを開き、「ロール」→作成したロール(「test-role-1ss45ahi」等)→「AWSLambdaBasic…」を選択します。
「このポリシーで定義されている許可」メニューの右上の「編集」を押します。
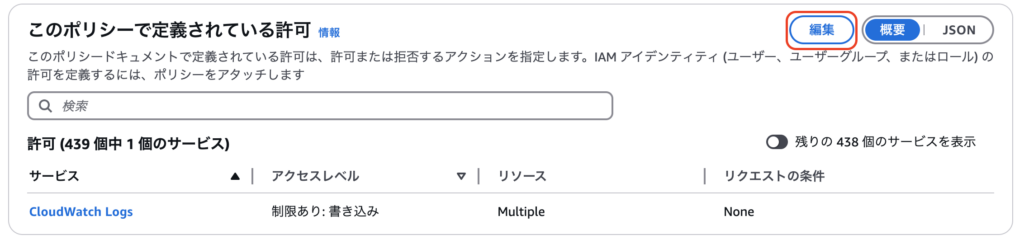
JSON形式で許可する権限を記述できるようになっているので、下記のエンティティを追記します。配置したファイルを参照できるようGetObjectおよびListBucketも記述しておきます。
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::[バケット名]/*",
"arn:aws:s3:::[バケット名]
]
},
{
"Effect": "Allow",
"Action": "secretsmanager:GetSecretValue",
"Resource": "[Secrets ManagerのARN]"
}[バケット名]および[Secrets ManagerのARN]の部分はご自身の環境に合わせて指定してください。Secrets Managerの画面からARNを確認・コピーできます。
では、Lambdaに戻って「Lambdaのロール作成」章で作成した関数にスクリプトを記述していきます。本章のスクリプト記述画面のゴールイメージは以下です。
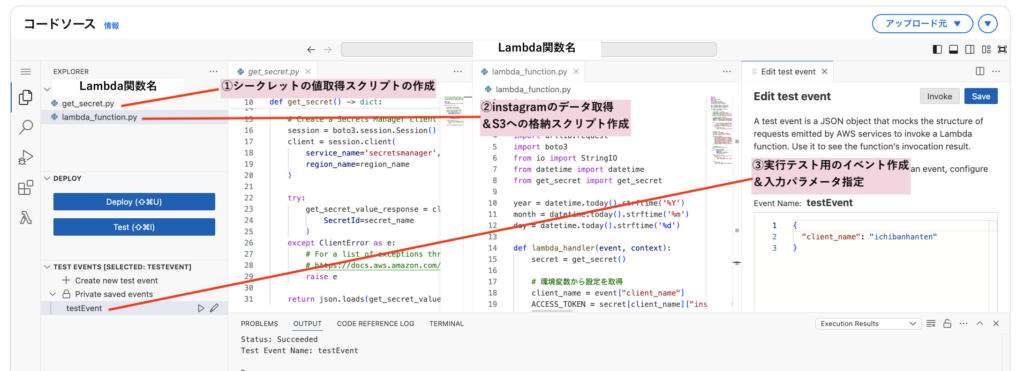
get_secret.pyというファイルを作成し、下記を記述します。
# Use this code snippet in your app.
# If you need more information about configurations
# or implementing the sample code, visit the AWS docs:
# https://aws.amazon.com/developer/language/python/
import json
import boto3
from botocore.exceptions import ClientError
def get_secret() -> dict:
secret_name = "secrets-to-call-API" # シークレット名
region_name = "ap-northeast-1" # リージョン
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
except ClientError as e:
# For a list of exceptions thrown, see
# https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html
raise e
return json.loads(get_secret_value_response['SecretString'])12、13行目のシークレット名およびリージョンは環境に合わせて変更します。
続いて、すでにテンプレートとしてある「lambda_function.py」に下記を記述します。まるまる上書きでOKです。
import os
import json
import csv
import urllib.request
import boto3
from io import StringIO
from datetime import datetime
from get_secret import get_secret
year = datetime.today().strftime('%Y')
month = datetime.today().strftime('%m')
day = datetime.today().strftime('%d')
def lambda_handler(event, context):
secret = get_secret()
# 環境変数から設定を取得
client_name = event["client_name"]
ACCESS_TOKEN = secret[client_name]["instagram"]
S3_BUCKET = "test-bucket-instagram-2025" # S3のバケット名を指定
S3_KEY = f'{client_name}/{year}/{month}/{day}/profile.csv'
# Instagram APIエンドポイント
INSTAGRAM_API_URL = 'https://graph.facebook.com/v17.0/****IG_USER_ID*****/'
# "ichibanhanten.official"の部分も本来入力パラメータなどに含めるべき。
PARAMS = 'fields=business_discovery.username(ichibanhanten.official){name,username,biography,follows_count,followers_count,media_count}&' + f'access_token={ACCESS_TOKEN}'
FULL_URL = f'{INSTAGRAM_API_URL}?{PARAMS}'
try:
with urllib.request.urlopen(FULL_URL) as response:
data = json.loads(response.read().decode())
except urllib.error.URLError as e:
print(f"Error fetching Instagram data: {e}")
return {
'statusCode': 500,
'body': json.dumps('Error fetching Instagram data')
}
# CSVデータ作成
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
csv_writer.writerow(['name', 'username', 'biography', 'follows_count', 'followers_count', 'media_count', 'id','date_get_data'])
csv_writer.writerow([
data['business_discovery']['name'],
data['business_discovery']['username'],
data['business_discovery']['biography'],
data['business_discovery']['follows_count'],
data['business_discovery']['followers_count'],
data['business_discovery']['media_count'],
data['business_discovery']['id'],
datetime.today().strftime('%Y-%m-%d'),
])
# S3へアップロード
s3_client = boto3.client('s3')
try:
s3_client.put_object(
Bucket=S3_BUCKET,
Key=S3_KEY,
Body=csv_buffer.getvalue(),
ContentType='text/csv'
)
except Exception as e:
print(f"Error uploading to S3: {e}")
return {
'statusCode': 500,
'body': json.dumps('Error uploading to S3')
}
return {
'statusCode': 200,
'body': json.dumps(f'Data successfully uploaded to {S3_BUCKET}/{S3_KEY}')
}
上部で指定した固定値について、注意点があるので紹介します。
一通り記述できたら、「Deploy」ボタンでデプロイします。
では、最後に入力パラメータを指定します。入力パラメータはJSON形式で記述することで、lambda_handler関数のevent変数より辞書型で参照できるようになります。
TEST EVENTS欄からテストイベントを作成します。イベント名は任意でOKです。
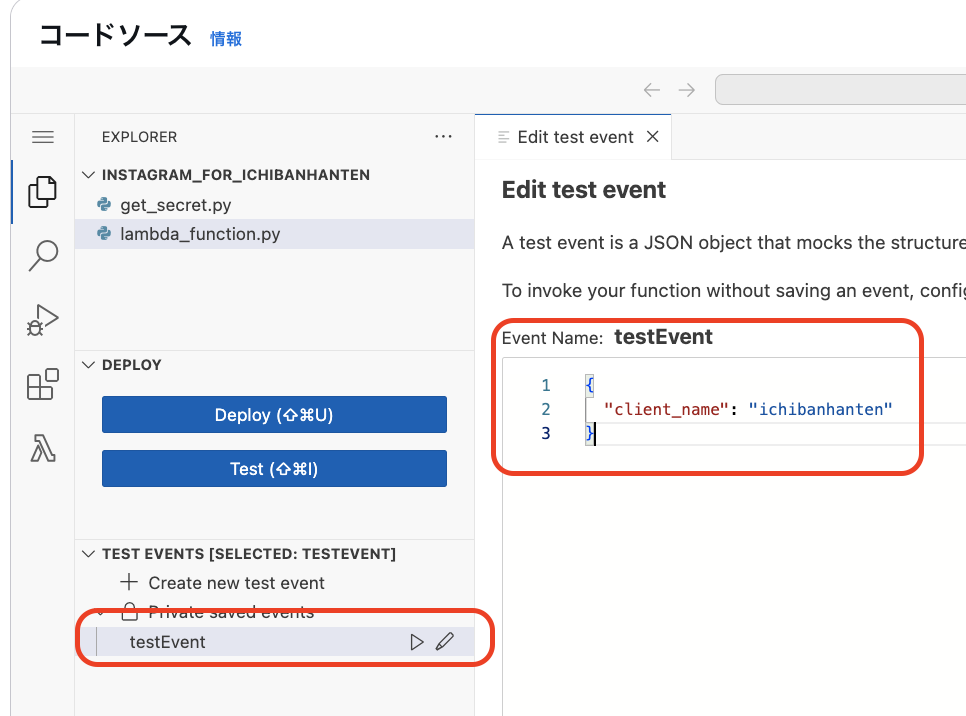
今回はクライアント名を入力パラメータとして下記のように入力します。
{
"client_name": "ichibanhanten"
}作成したイベント(画像では「testEvent」)の横にある三角ボタンを押して実行してみます。うまく設定できていれば、実行後しばらくして下記のように「Data successfully …」という結果がでます。

もし、下記のようなタイムアウトのエラーが出た場合、「設定」タブからタイムアウト時間を変更しましょう(デフォルトは3秒)。
Response:
{
"errorType": "Sandbox.Timedout",
"errorMessage": "RequestId: ****-****-****-****-**** Error: Task timed out after 3.00 seconds"
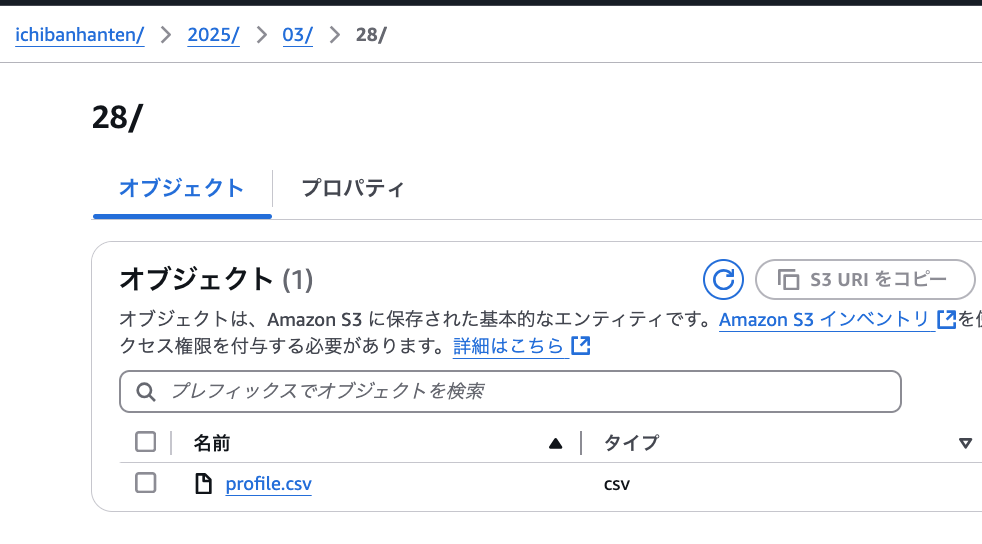
}では実際にS3の当該パスにCSVが格納されたか確認しましょう。[バケット名]/クライアント名/年/月/日/profile.csvが問題なく格納されていますね!
次章のスケジュール実行用に、Lambda関数の呼び出しができるようロールに権限を追加します。IAMのメニューから「ロール」→「ポリシー」を選択し、JSONに下記を追記します。
{
"Sid": "invokeLambdaFunction",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "[Lambda関数のARN]"
}では最後に、日次などで実行できるよう設定します。EventBridgeというサービスから行います。メニューでEventBridgeを開き、左のペインから「スケジュール」を選択します。

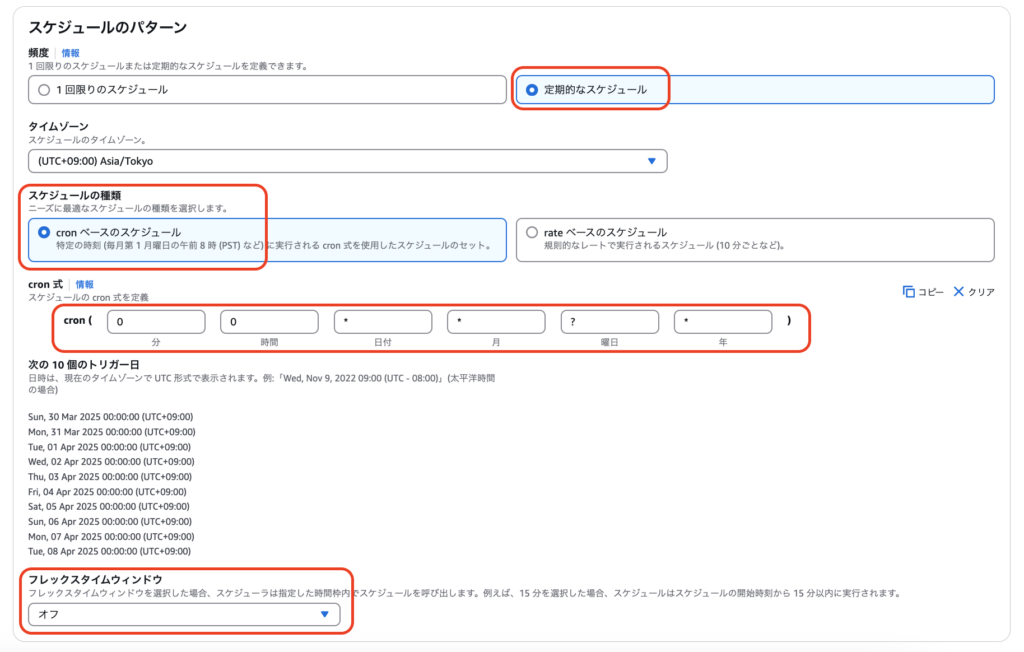
続いて、イベントスケジュールおよび実行タイミングを指定します。まずはスケジュール名を設定します。

実行タイミングについては、ロケール(Asia/Tokyoなど)を選択後、「0 0 * * ? *」とすることで毎日0時0分に実行されるようになります。フレックスタイムは特段なければオフでよいでしょう。
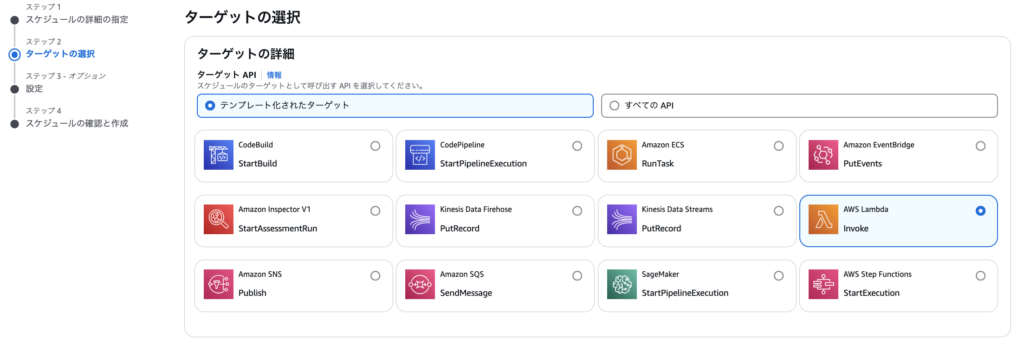
ステップ2として定期実行するアプリケーションを選択します。今回はLambdaを選択します。
Lambda関数および入力パラメータを設定します。前章-「入力パラメータを指定」節で、テストとして指定したJSON形式の文字列を設定します。
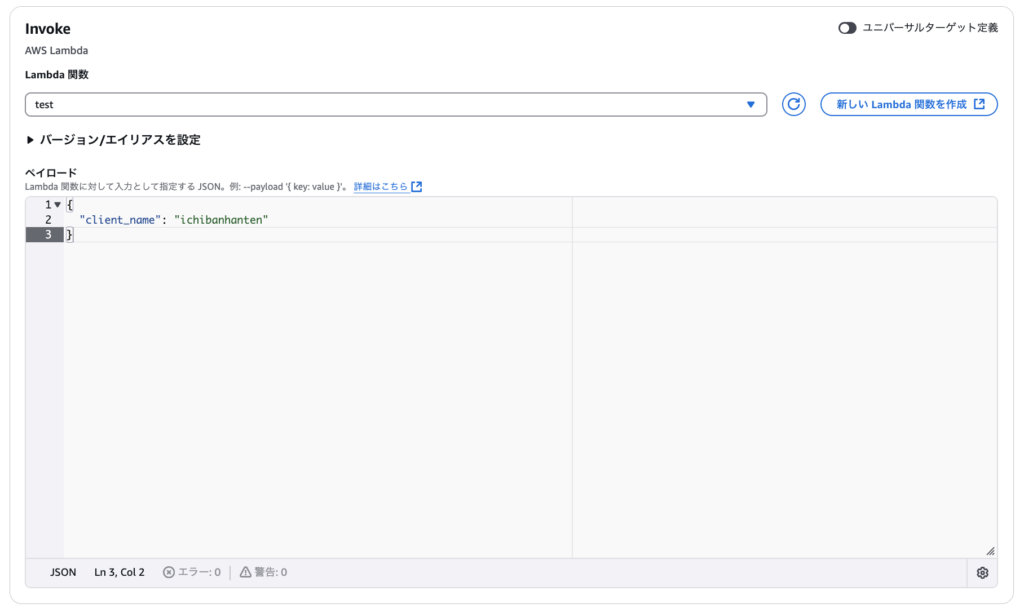
{
"client_name": "ichibanhanten"
}前述した通り、このJSONはLambdaに記述したlambda_handler関数の引数「event」より辞書型で参照できるようになります。
ステップ3として、タスク実行が失敗したときの挙動など詳細を設定します。この部分は要件に合わせて指定してください。タスク自体の有効化は忘れないように!
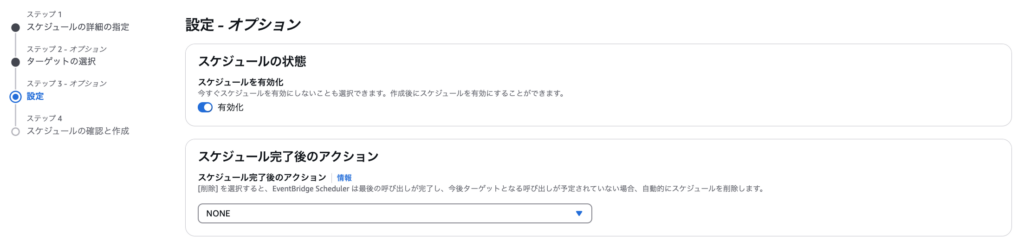
大事なポイントとして、実行ロールを指定します。ここでは、Lambdaの実行ロール(例では「test-role-1ss45ahi」)を必ず指定します。
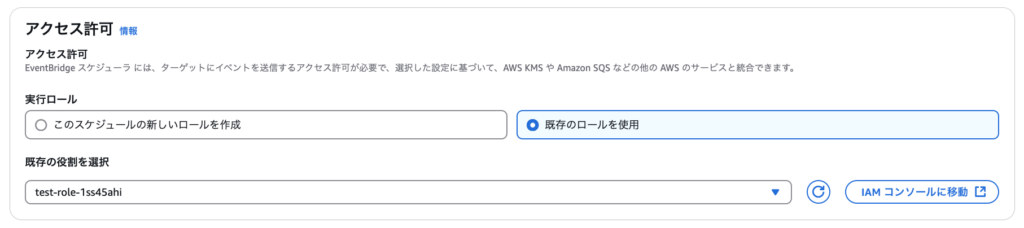
「次へ」を押下し最後にタスク設定全体を確認し、スケジュールの作成は完了です。指定したタイミングで、S3内に年月日のフォルダパス+CSVファイルが格納されていることを確認しましょう!
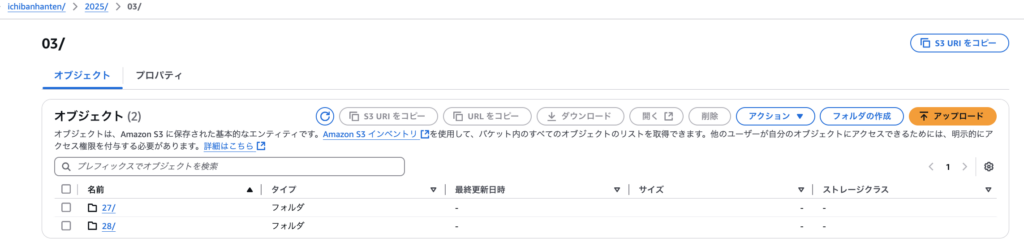

クライアント名/年/月/日のフォルダ構成で日々ファイルが作成されていきます。(通知サービスを組むとより良いですが)エラーが発生した時は、その日のフォルダも作られないので抜け漏れも確認しやすいですね!
本記事ではAWSの仕組みを使って外部サービス(Instagram)のデータを取得・格納まで行う仕組みを紹介しました。
S3に格納したCSVデータをSnowflakeのテーブルへインポートする方法はこちらで紹介しているので併せてご覧ください。
「Snowflakeから直接データを取得・格納はだめ?」章でも述べたように、Snowflakeの良い部分を取りつつ、PythonのコンピューティングコストをAWS側に寄せ、よりコスパの良い仕組みを構築できるとよいですね。