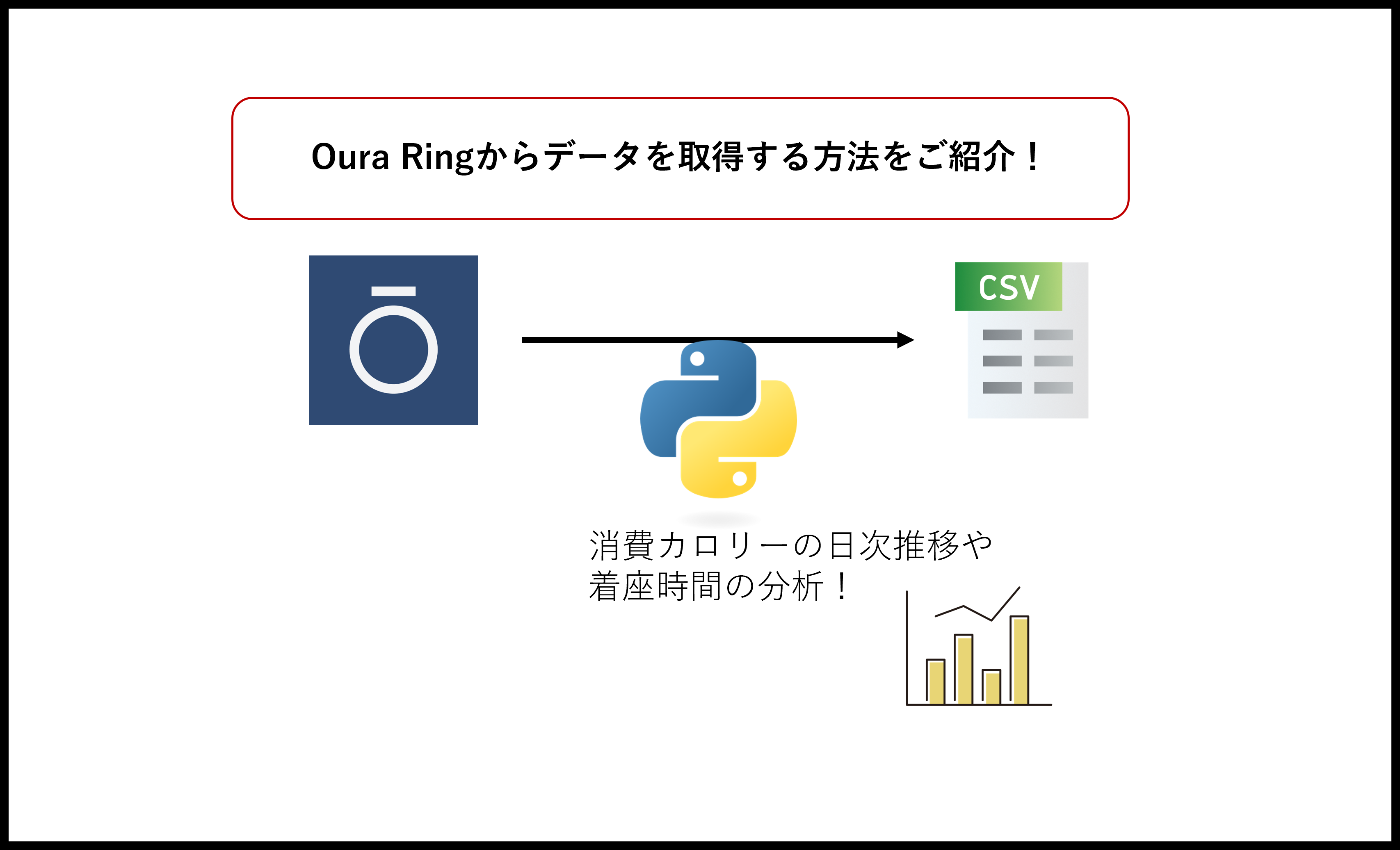
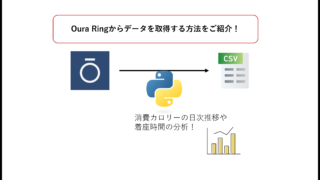
APIを使ったデータ取得・加工処理をしたときSnowflake/AWSどちらのコストが安い?
えび
データパレード


みなさんは日々の日常の中でどれくらい生成AIを使っているでしょうか? 2024年はあらゆる人が生成AIを活用できる時代となりました。おそらく会社での日々の業務に特化した個別最適型のAIも今後登場するでしょう。
上司から「あなたの業務をAI使って」と言われたらもう遅い。そうなるはるか前から自分の業務をAIに置き換えることを考えねば、仕事はどんどんと減っていくでしょう。
これから先、AIの活躍により仕事もプライベートもますます快適になるでしょう。そんな未来が待っているとして、私たちは何をしておけばいいのか。私は今からでも「データを溜めること」に注力すべきと思います。
その理由について解説をしていきたいと思います。
AI時代におけるデータ蓄積の重要性とどのようにデータを溜めていけばいいのかの方針について、ぜひご覧になってください。

データ蓄積における重要性は昔から語られ続けてきました。人間が判断するために過去のデータを溜めることを行なっていました。
しかしあくまでも基幹システムのデータの可視化といったところでしょう。社外データと併せてデータ活用する企業は先端を進んでいる感じがしました。
なぜなら、かつてはデータを溜めることにも、データの活用方法を考えることにも課題があったからです。

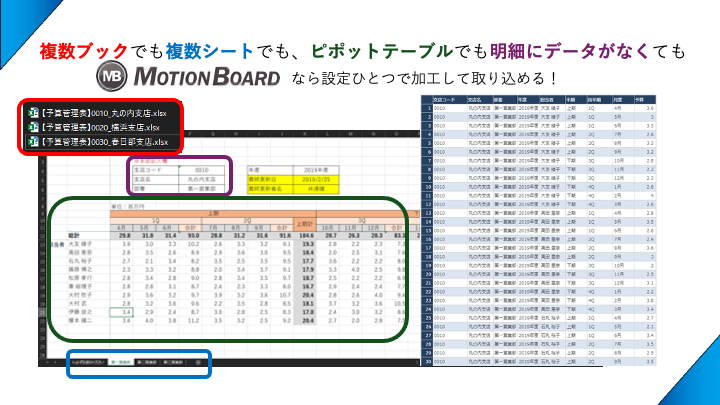
こちらはデータを抽出してから可視化をするまでに必要なステップを記載した図です。この発生したばかりのデータを蓄積する”データレイク”が重要なポイントとなります。
現代でこそハードウェアが強化されたことで、データレイクに大量のデータを投入することができていますが、少し前の時代はデータレイクはありませんでした。また現代のデータレイクは非構造化データ(画像や動画、音声など)を蓄積することも可能です。データを溜められる方法がどんどんと確立されてきているのですね。
かつてよりもデータ蓄積をすることが容易になりました。しかし今でも「このデータは将来役に立つかもしれない」というものを蓄積しておく傾向は少ないと思います。それは今までの発想だと「そのデータが本当に価値のあるものなのかを導き出すのは人間」と考えているからです。
大量のデータであればあるほど、そのデータたちの関連性を見つけ、検証し、業務に役立てることには大変な手間と知恵がかかります。
現代ではまだ厳しいかもしれませんが、この仕事はAIの得意分野になっていくと思います。AIに大量のデータを読んでもらいさまざまな仮説を提案してもらって、人間はその候補の中から判断をする役割を担えばいいのです。
今の段階ではどうしてもこの部分を人間がやろうと考えてしまうので、
となってしまっているように思えます。では、ここからは「なぜ今、データ蓄積をする必要があるのか」を解説します。

当たり前の話ですね。この1年間を見てみても、AIがものすごい勢いで進歩していることがわかります。これからもその成長のスピードはとても期待できるでしょう。
ただし現時点のAIでは、みなさんの想像する世界は訪れていないと思います。これが徐々にみなさんの納得するAIができてくると思います。
そんな世界が来る中で、進化したAIでもできないことがあります。それは「過去のデータは作れない」ということ。
企業で考えてもいくらその時にAIが進化していても、過去数年の売上データや従業員情報などの昔のデータがなければAIが判断する術がありません。決算書とかを読ませることはできますが、ローデータがない限り、細かな分析ができないのです。
未来のAIに渡す素材として、データの蓄積をするのです。

今までを振り返りながら要点をまとめます。
データの蓄積が重要です。なぜならば未来のAIに参考にしてもらう情報を作るためです。かつてはデータレイクがなく、データマイニングも人間がやる想定でいたため、必要最低限のデータ蓄積しか考えていませんでした。でもこれからの時代は”まずはデータを溜めてみる”という発想が重要になってきます。
これは余談ですが、私はパーソナルデータもどんどん蓄積するようにしています。その一例を別記事で紹介していますので、興味のある方はぜひ参照してください。
また、今は会議や日々の会話の録音データを溜める検証をしています。これはまさに非構造化データの蓄積です。会議の要約やネクストアクションの設定などは自動でやってくれます。さらに会話の中の話者を分けて保管することもできています。
このデータを蓄積していくと、誰とのコミュニケーションが頻繁かを特定することも容易ですし、話者それぞれの話し方を分析してプレゼンのアドバイスができたり、心理状態を読み取ることなどもできてくると思います。それらができるAIができる前に、過去のデータを蓄積しておくということが重要です。

つよっつよの完璧なAIが出た頃には、データはわざわざ一箇所に蓄積する必要はなく、あちらこちらからAIが自動でデータをとってきて分析してくれるかもしれません。ですがそのような素晴らしいAIはまだまだ出てこないでしょう。
未来のAIのレベルにあわせてデータの溜め方を検討すればいいんじゃないかなと思います。
例えば今後、音声データや録画データをAIに読んでもらいたいのであれば、まずはデータを保存しましょう。どこかのデータベースに入れるではなく、まずはクラウドストレージでも自分の端末にでも蓄積をしていくことが大事です。
できれば要約と生データはセットにしておきたいですね。要約はメタデータとなり、AIの分析を助けることでしょう。録音+要約などをしてくれ、さらに生データを手元に残せる仕組みがあるといいです。
構造かデータだったら、どこかに自動で蓄積する仕組みを作っておきたいですね。
AIもたくさんの場所からデータを引っ張ってくると大変です。分析に使うデータはなるべく一箇所に溜めておきましょう。データレイクとして活用できるものがあるといいですね。
Snowflakeのようなクラウド型のDBがオススメです。
私もその様な意図で構造化データはデータベースに蓄積しています。

ローデータで保管することは鉄則ですが、データ可視化用のデータマートを作っておくのもいいですね。AIがデータ加工をしてくれる未来もまだ時間がかかりそうですので、分析しやすい形でデータウェアハウスやデータマートを用意しておくこともオススメです。
ここはAI関係なく、先行してデータ可視化に着手をすれば、自ずとデータマートはできていくでしょう。
このような形で、早くAIでデータ活用をしたければ、AIの進化を逆算してデータを用意しておくことが良いと考えます。

人間にとってかつてない体験をできる機会はもう目の前です。データの重要性はITバブル当初から出始めていましたが、ここしばらくはデータ可視化などUIの方に話がいきがちでした。
AIの登場により、データ可視化は衰退していくものと考えます。なぜなら可視化はAIに置き換えられる領域だから。
これからの未来でAIを相棒として扱う時代に、AIにパーソナル情報をいかに理解してもらうかが鍵となります。AIにたくさん自分たちを知ってもらうことが、今後の差別化ポイントとなってきます。
ぜひ今から、AIに知ってもらえる情報、つまりデータをたくさん集めるようにしましょう。