生成AIとデータ蓄積の重要性
Ryosuke Ishii
データパレード

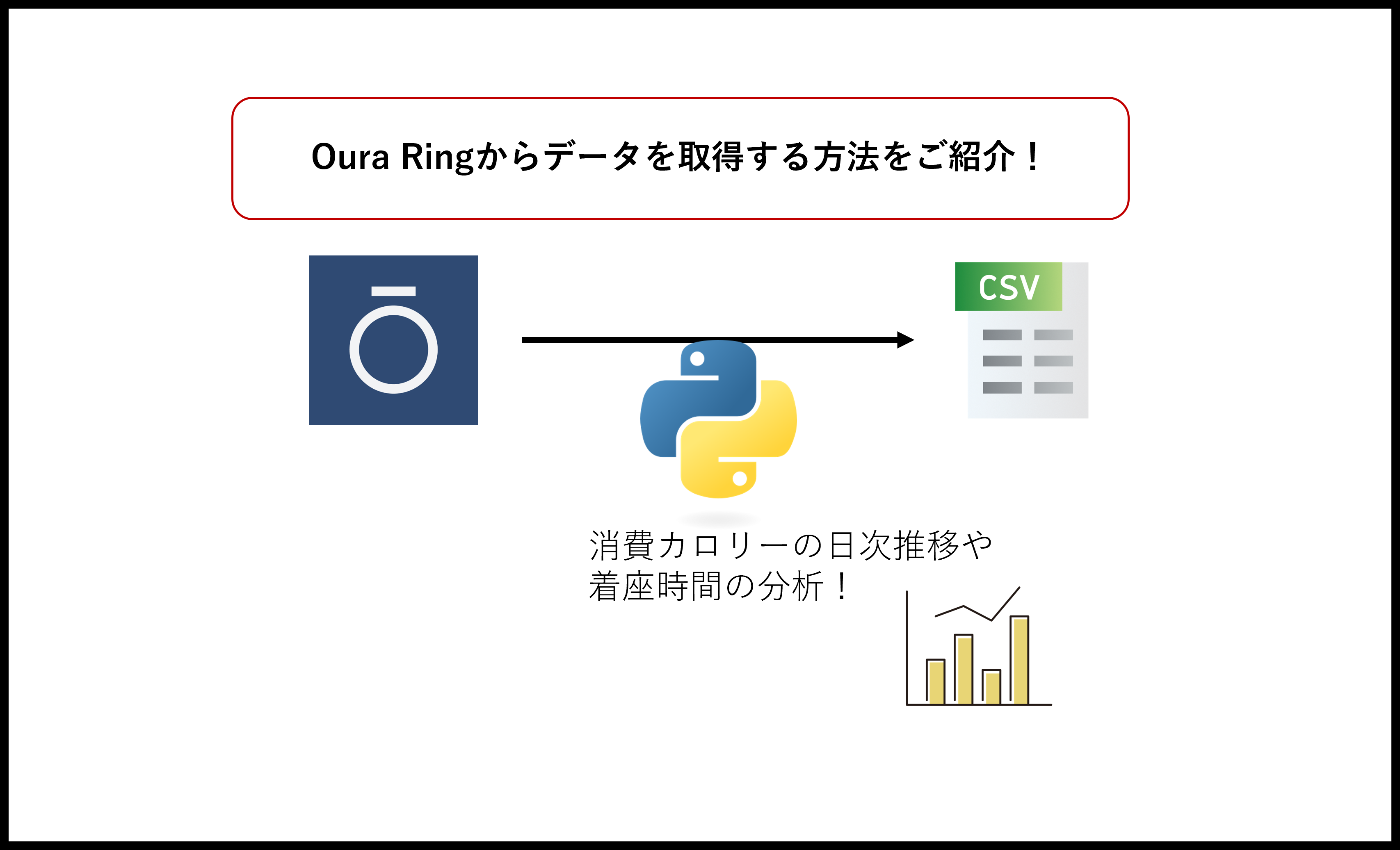
Oura Ringと呼ばれる指輪型のスマートデバイスでは、装着するだけで日々の睡眠情報やアクティビティ情報を収集することができます。
ただ、データは集めるだけでは意味がなく、グラフなどで可視化して「今週は〇〇kmも歩いたのか!」だったり「座ってる時間が長い、まずいぞ!」といった気づきが得られるとおもしろいですね。
Oura Ringでは、デバイスから収集した情報をWeb APIを使って取り出すことができます。本記事では、Web APIを使ってOura Ringのアクティビティ情報を取得する方法を紹介します。
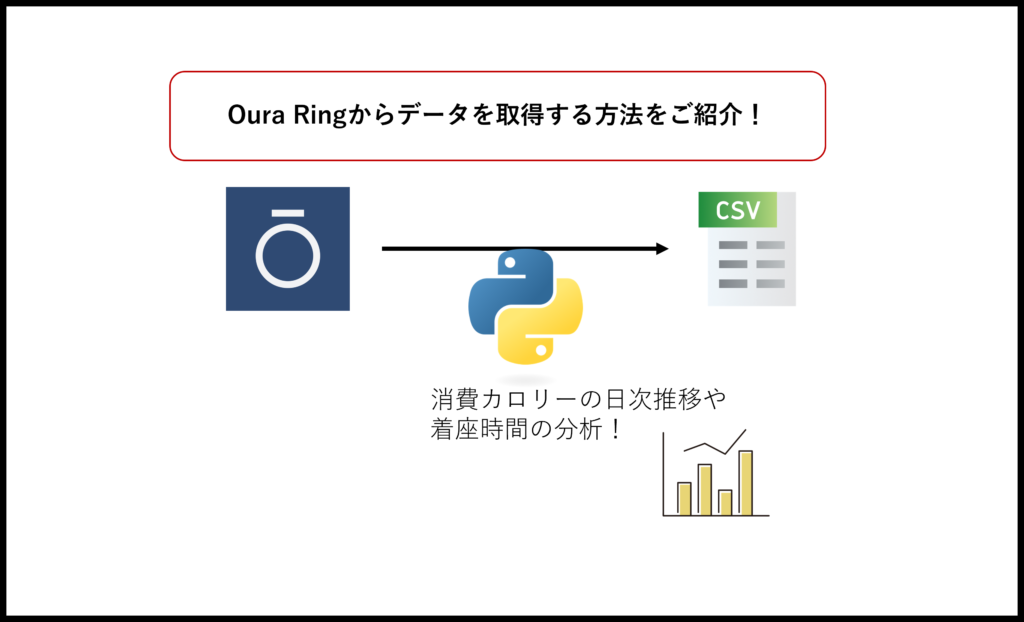
具体的には、Oura RingのWeb APIを呼び出し、BIツール等で分析しやすいよう加工し、結果をCSVファイルに出力するまでをPythonを使って実装します。
今回はCSVに出力ですが、Google Sheetに入れる方法も別記事で記載しています。
Ouraの開発者向けページにログインし、アクセストークンを発行しましょう。
まずはPythonのことは置いておいて、どのようにWeb APIを使えるのか、どんなデータが取れるのかを確認してみましょう。
本記事では、Talend API Testerと呼ばれるブラウザベースでWeb APIを呼び出し、結果を確認することができるツールを使っていきます。Web APIのテストからPythonで自動化するまでの流れはこちらの記事で解説しておりますので是非!
では早速みてみましょう。Oura Ringでは取得できる情報もたくさんあり、その分用意されているエンドポイントも多いので、なかでも今回は日ごとのアクティビティ情報を取得するAPIを例に紹介します。
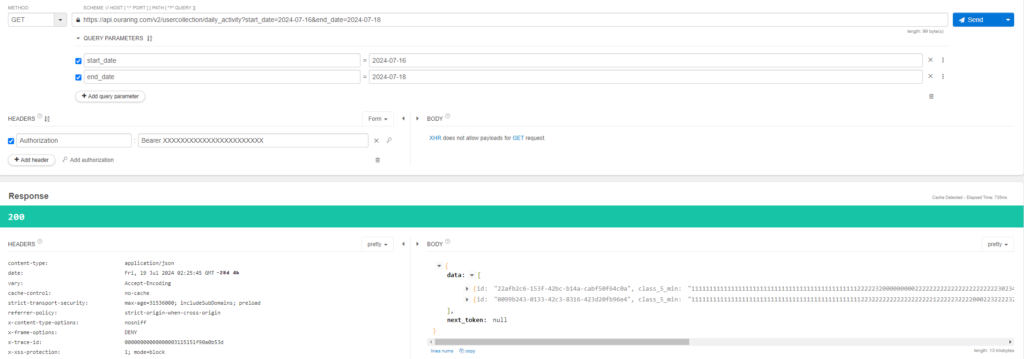
下記のように指定してみてください。
・画像左上「METHOD」:GET
・画像上部のURL:https://api.ouraring.com/v2/usercollection/daily_activity?start_date=2024-07-16&end_date=2024-07-18
※ start_date及びend_dateは取得したい日付の範囲を指定
・画像中央左「HEADER」:[+Add Header]を押下し、「Authorization」/「Bearer <Access Token>」と指定
Access Tokenの取得については、Web APIのドキュメントにて記載がありますのでこちらをご覧ください。
右上の「Send」ボタンを押下し、問題がなければResponseエリアにて「200」の数字が表示されます。結果を見てみましょう。
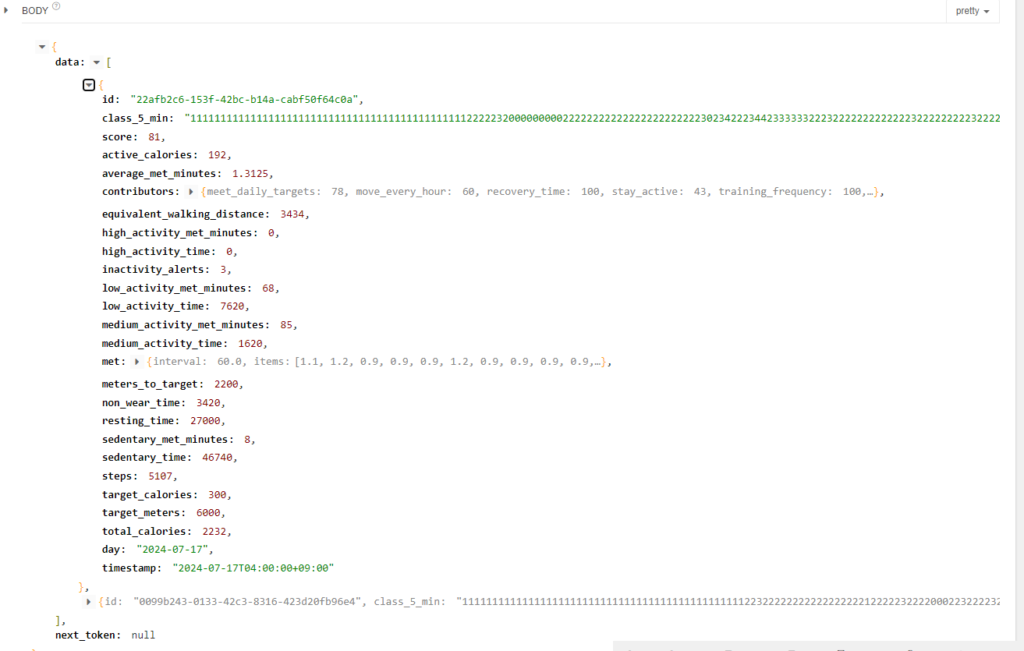
各指標の詳細については今回割愛しますが、消費カロリー(active_calories)や着座時間(sedentary_time)、歩数(step)など様々な指標が取れていることがわかります。また、5分ごとの活動状態を0~5の羅列で表現されている指標(class_5_min)といったものもあります。
以上でWeb APIを使ってデータが取れることが確認できました。ここからは、取得したデータを例えば日ごとの推移でみたり、統計を見たりと、ExcelやBIツールで分析できるよう加工していきます。
全体のソースコードはこちらからどうぞ。使い方についてもREADMEにて記載しています。このうち、本記事では日々のアクティビティデータの取得について紹介します。
import argparse
import logging.handlers
import requests
import configparser
import logging
import pandas as pd
import datetime
# python .\daily_activity.py -configfile_path "C:/Workspace/python/oura_ring/config/config.ini" -start_date 2024-08-01 -end_date 2024-08-10 -output_path "C:/Workspace/python/oura_ring/output"
# args
parser = argparse.ArgumentParser(description='')
parser.add_argument('-configfile_path', help="C:/Workspace/python/oura_ring/config/config.ini")
parser.add_argument('-start_date', help='yyyy-MM-dd')
parser.add_argument('-end_date', help='yyyy-MM-dd')
parser.add_argument('-output_path', help="C:/Workspace/python/oura_ring/output")
args = parser.parse_args()
# config
config_ini = configparser.ConfigParser()
config_ini.read(args.configfile_path, encoding='utf-8')
# logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
format = "%(levelname)-9s %(asctime)s [%(filename)s:%(lineno)d] %(message)s"
st_handler = logging.StreamHandler()
st_handler.setLevel(logging.DEBUG)
st_handler.setFormatter(logging.Formatter(format))
fl_handler = logging.handlers.TimedRotatingFileHandler(filename= config_ini["LOG"]["PATH"] + "/" + config_ini["LOG"]["FILENAME"] + ".log", encoding="utf-8", when = "MIDNIGHT")
fl_handler.setLevel(logging.DEBUG)
fl_handler.setFormatter(logging.Formatter(format))
logger.addHandler(st_handler)
logger.addHandler(fl_handler)
logger.info("start daily_activity")
URL = "https://api.ouraring.com/v2/usercollection/daily_activity"
HEADER = {
"Authorization": "Bearer " + config_ini["DEFAULT"]["TOKEN"]
}
params = {
"start_date": args.start_date,
"end_date": args.end_date,
"next_token": ""
}
# class_5_min のデータ取得用
OURA_RING_INTERVAL = 5
basic_data ={
"id": [],
"score": [],
"active_calories": [],
"average_met_minutes": [],
"meet_daily_targets": [],
"move_every_hour": [],
"recovery_time": [],
"stay_active": [],
"training_frequency": [],
"training_volume": [],
"equivalent_walking_distance": [],
"high_activity_met_minutes": [],
"high_activity_time": [],
"inactivity_alerts": [],
"low_activity_met_minutes": [],
"low_activity_time": [],
"medium_activity_met_minutes": [],
"medium_activity_time": [],
"meters_to_target": [],
"non_wear_time": [],
"resting_time": [],
"sedentary_met_minutes": [],
"sedentary_time": [],
"steps": [],
"target_calories": [],
"target_meters": [],
"total_calories": [],
"day": [],
"timestamp" : []
}
activity_per_5_min = {
"id": [],
"start_recording": [],
"end_recording": [],
"status_number": []
}
def main():
status_code = 200
next_token_flag = True
loop_cnt = 0
while(status_code == 200 and next_token_flag is True):
res = requests.get(url = URL, headers = HEADER, params = params)
status_code = res.status_code
if(res.status_code == 200):
data = res.json()["data"]
print(res.json()["next_token"])
if res.json()["next_token"] is None:
next_token_flag = False
params["next_token"] = ""
else:
next_token_flag = True
params["next_token"] = res.json()["next_token"]
print(loop_cnt, status_code, next_token_flag)
# basic info
for b_data in data:
for key, value in b_data.items():
if(key in basic_data):
basic_data[key].append(value)
elif(key == "contributors"):
for cntr_k, cntr_v in b_data["contributors"].items():
if(cntr_k in basic_data):
basic_data[cntr_k].append(cntr_v)
output_file_path = args.output_path + "/" + args.start_date + "~" + args.end_date + ".csv"
print(output_file_path)
pd.DataFrame(data = basic_data).to_csv(output_file_path, encoding = "utf-8", index = False)
# activity_per_5_min
for b_data in data:
start_timestamp = datetime.datetime.strptime(b_data["day"], '%Y-%m-%d')
end_timestamp = datetime.datetime.strptime(b_data["day"], '%Y-%m-%d') + datetime.timedelta(minutes = OURA_RING_INTERVAL)
for status_number in b_data["class_5_min"]:
activity_per_5_min["id"].append(b_data["id"])
activity_per_5_min["start_recording"].append(start_timestamp)
activity_per_5_min["end_recording"].append(end_timestamp)
activity_per_5_min["status_number"].append(status_number)
start_timestamp = start_timestamp + datetime.timedelta(minutes = OURA_RING_INTERVAL)
end_timestamp = end_timestamp + datetime.timedelta(minutes = OURA_RING_INTERVAL)
output_file_path = args.output_path + "/" + args.start_date + "~" + args.end_date + "_per5min.csv"
pd.DataFrame(data = activity_per_5_min).to_csv(output_file_path, encoding = "utf-8", index = False)
loop_cnt+=1
else:
logger.error(f"status code {res.status_code}: {res.reason}")
logger.info(f"configfile path:{args.configfile_path}")
logger.info(f"start date:{args.start_date}")
logger.info(f"end date:{args.end_date}")
logger.info(f"output path:{args.output_path}")
Exception(f"status code {res.status_code}: {res.reason}")
if __name__ == "__main__":
main()設定ファイルにアクセストークンを記載し、下記のように実行が可能です。
python .\daily_activity.py
-configfile_path "C:/Workspace/python/oura_ring/config/config.ini"
-start_date 2024-08-01
-end_date 2024-08-10
-output_path "C:/Workspace/python/oura_ring/output"実行すると、指定したフォルダに2つのCSVファイルが出力されます。
★yyyy-MM-dd~yyyy-MM-dd.csv
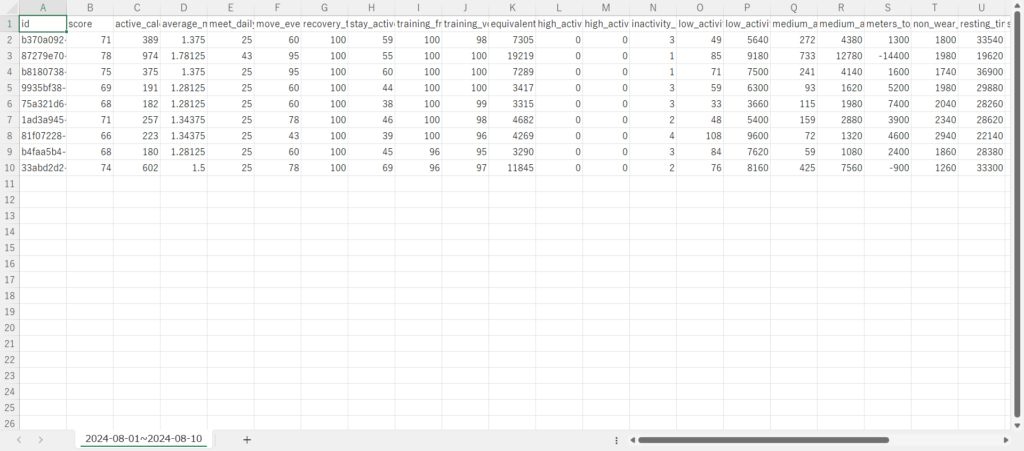
各指標が、日ごと(日付データは’day’カラム)に出力されます。
★yyyy-MM-dd~yyyy-MM-dd_per5min.csv
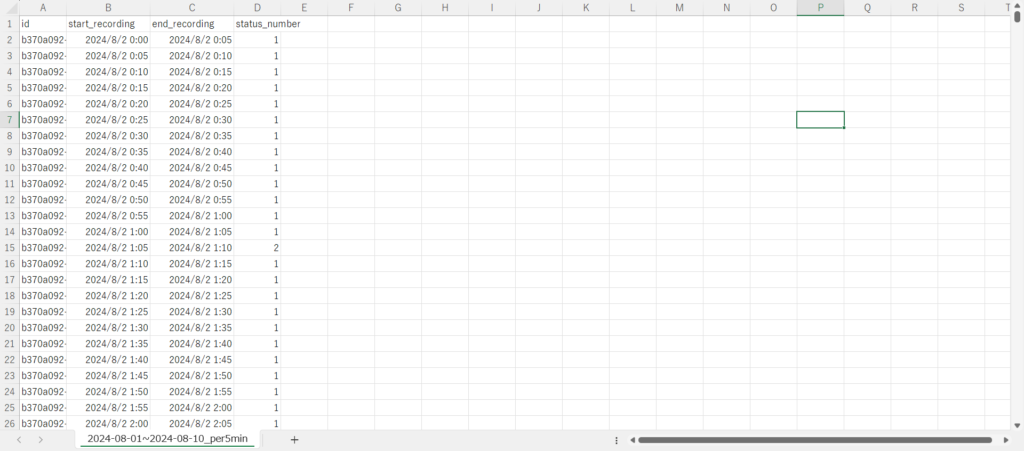
各指標の意味するところは下記の記事が大変参考になります。
指標「class_5_min」を5分ごとのタイムスタンプとして縦方向に展開し出力されます。「status_number」の各数値が意味するところは下記のようになっています。
0:non wear(リング未着用)
1:rest(休憩中)
2:inactive(非活動時間)
3:low activity(活動レベル<低>)
4:medium activity(活動レベル<中>)
5:high activity(活動レベル<高>)こちらのCSVファイルをExcelやBIツールなどで分析することで、日ごとの消費カロリーや歩数の分析、5分毎の細かい単位で自身の活動記録を確認することができますね!
本記事ではOura RingのWeb APIを使ってアクティビティ情報を取得し、扱いやすい形で加工・出力する方法を紹介しました。今回取り扱ったのはアクティビティ情報ですが、そのほか睡眠情報や血圧などのヘルスケア情報も取得できるので、組み合わせて分析しても面白そうですね。